Measuring Performance Under Failures in the LHCb Data Acquisition Network
Eloise Noelle Stein , Cristel Pelsser , Flavio Pisani and Tommaso Colombo
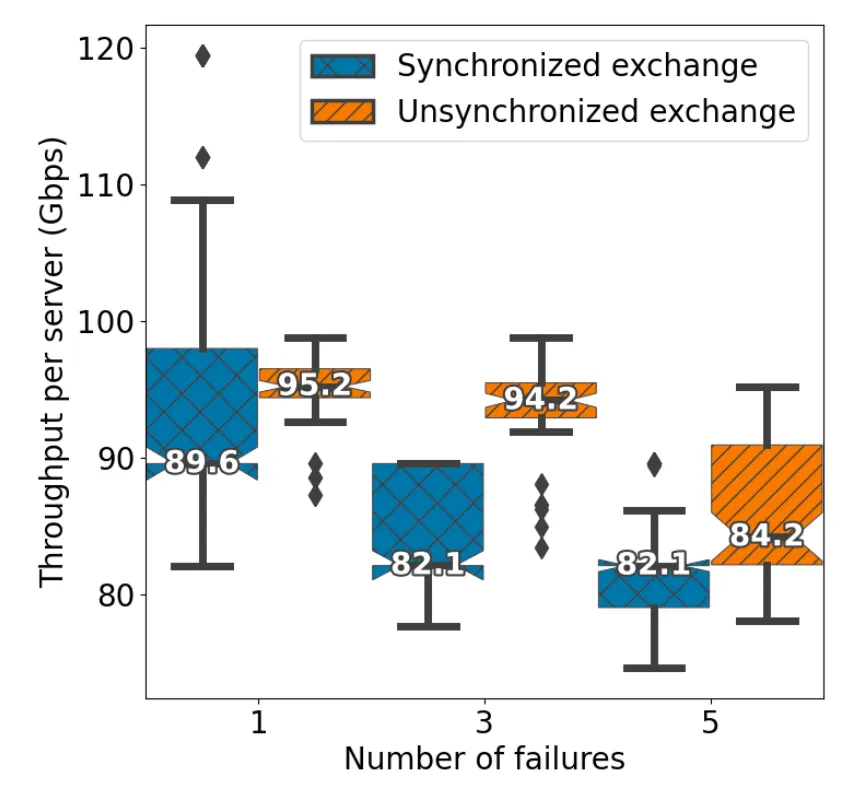
This 2024 conference poster, by Eloise Noelle Stein and 3 coauthors, was presented at 24th IEEE Real Time Conference - ICISE. Topics covered include data acquisition, network failures, performance measurement, and lhcb.
Full author list: Eloise Noelle Stein, Cristel Pelsser, Flavio Pisani, and Tommaso Colombo.
Abstract
In this paper, we study two possible approaches to high-performance event building on the data acquisition (DAQ) system of the LHCb experiment. We show, using live experiments, that a synchronized design, that carefully schedules network communications to avoid network congestion, can obtain significantly better performance than a looser approach. However, this comes at the price of fault tolerance: we study the performance degradation of the DAQ system in the presence of various link failures, showing that, in these scenarios, the synchronized approach is not optimal. Finally, we derive some design recommendations to make synchronized designs cope with network failures.
Publication Details
- Publication Type
- poster
- Publication Date
- April 2024
- Published In
- 24th IEEE Real Time Conference - ICISE
- Location
- Quy Nhon, Vietnam
- External Link
- https://indico.cern.ch/event/940112/contributions/…
Suggested citation
Eloise Noelle Stein, Cristel Pelsser, Flavio Pisani, and Tommaso Colombo. 2024. Measuring Performance Under Failures in the LHCb Data Acquisition Network. In 24th IEEE Real Time Conference - ICISE. Quy Nhon, Vietnam.
BibTeX Citation
BibTeX Citation
@poster{Stein2024,
title = {Measuring Performance Under Failures in the LHCb Data Acquisition Network},
author = {Eloise Noelle Stein and Cristel Pelsser and Flavio Pisani and Tommaso Colombo},
year = 2024,
month = apr,
day = 23,
booktitle = {24th IEEE Real Time Conference - ICISE},
address = {Quy Nhon, Vietnam},
url = {https://indico.cern.ch/event/940112/contributions/5765003/},
abstract = {In this paper, we study two possible approaches to high-performance event building on the data acquisition (DAQ) system of the LHCb experiment. We show, using live experiments, that a synchronized design, that carefully schedules network communications to avoid network congestion, can obtain significantly better performance than a looser approach. However, this comes at the price of fault tolerance: we study the performance degradation of the DAQ system in the presence of various link failures, showing that, in these scenarios, the synchronized approach is not optimal. Finally, we derive some design recommendations to make synchronized designs cope with network failures.},
affiliation = {Universite de Strasbourg (FR)},
coauthors = {Cristel Pelsser (UCLouvain and University of Strasbourg), Flavio Pisani (CERN), Tommaso Colombo (CERN)},
duration = {1h},
groups = {Posters},
keywords = {Data Acquisition, Network Failures, Performance Measurement, LHCb},
session = {Data Acquisition and Trigger Architectures Poster A},
speaker = {Eloise Noelle Stein},
time = {11:55 AM},
type = {Mini Oral and Poster}
}
Related publications
FORS: Fault-adaptive Optimized Routing and Scheduling for DAQ Networks
Eloise Stein, Quentin Bramas, and Flavio Pisani, et al.
Computing and Software for Big Science, 2025
Measuring Performance Under Failures in the LHCb Data Acquisition Network
Eloise Stein, Flavio Pisani, and Tommaso Colombo, et al.
IEEE Transactions on Nuclear Science, 2024
Fault-adaptive Scheduling for Data Acquisition Networks
Eloise Noelle Stein, Cristel Pelsser, and Quentin Bramas, et al.
The 48th IEEE Conference on Local Computer Networks (LCN), 2023
Shared Antennas, Shared Risks
Alexandre Vogel and Cristel Pelsser
10th IEEE/IFIP Network Traffic Measurement and Analysis Conference (TMA 2026), 2026